Veri seti: Bu çalışmada yapılan yazılımın çalışma şeklini gösterebilmek ve çıktılarını değerlendirebilmek adına üç değişkenden oluşan her bir değişkenin sırasıyla üstel, gamma ve Cauchy dağılımları ile elde edildiği ve değişkenlerin 1000 gözlem içerdiği veri seti R Project versiyon (3.4.2) yazılımı
6 ile türetilmiştir.
Veri Dönüşüm Yöntemleri: Yapılacak çalışmalarda araştırıcılar genelde istatistiksel gücü ve etki büyüklüğü daha kuvvetli olan birinci ve ikinci tip hatalara karşı daha dirençli olan parametrik testleri seçme eğiliminde olup bu testleri seçmek adına bazı varsayımların gerçekleşip gerçekleşmediğini kontrol etmelidir. Bu varsayımlar örneklemlerin çekildiği evrenlerin normal dağılım göstermesi ve evren varyanslarının homojen olması varsayımlarıdır 3. Araştırıcılar bu nedenle öncelikle varsayımlardan biri olan verilerin normal dağılıma uygun olup olmadığını araştırmalıdır. Eğer veriler normal dağılıma uyuyor ve diğer varsayımlar sağlanıyor ise istatistiksel analizlerde parametrik testler kullanılmalıdır. Fakat veriler normal dağılıma uygunluk varsayımını sağlamıyor ya da varyansların homojenlik koşulunu sağlamıyor ise normal dağılıma uymadığı belirlenen ve homojenliği bozduğu düşünülen değişkenlere bazı dönüşümler yapılarak veri setinin normal dağılıma uygunluğu sağlanabilir. Yapılan bu dönüşümlere veri dönüşüm yöntemleri denir. Geliştirilen web tabanlı yazılımda arcsinh(x), Box-Cox, Üstel, Lambert W (h tipi), Lambert W (s tipi), Logaritmik, Karekök, Yeo-Johnson veri dönüşüm yöntemleri kullanılmıştır. Ayrıca yazılım dönüşüme tabi tutulacak veri seti için kullanılan veri dönüşümü yöntemleri içinde en iyi yönteme karar vermemizi sağlayacak olan Pearson P test istatistiğini hesaplayarak en iyi dönüşüm ile dönüştürülen veri setini indirmemize olanak sağlamaktadır. Bu işlemi yazılımda yer alan veri dönüşümü yöntemlerinin her biri için elde edilen Pearson P istatistiği değerlerinden en küçüğüne sahip dönüşümü seçerek yapmaktadır.
Logaritmik dönüşüm: Sağa ya da sola çarpık olup değişim aralığının ve merkezi simetrinin önemli olduğu veri setlerinde varyansa dengeleme dönüşümü olarak kullanılan bir veri dönüşüm yöntemidir. Dönüşümlerde en yaygın olarak 10 tabanındaki logaritmik dönüşüm tercih edilirken, doğal logaritma olarak adlandırılan e tabanlı logaritmik dönüşüm de kullanılmaktadır. Eğer veri seti sıfır ve negatif değerler içeriyorsa veri setinde yer alan tüm gözlemlere pozitif bir sayı eklenerek veri seti düzenlenir ve daha sonra dönüşüm yapılır. Kesikli bir veri seti ile ilgileniliyor ve veri setinde sıfır değerleri varsa her bir gözleme 0.5 değeri eklenerek dönüşüm yapılmalıdır. Veri setindeki tüm değerlerin logaritması alınarak işlemler yapılır ancak sonuçlar yorumlanırken veriler eski değerlerine dönüştürülmelidir 7.
Üstel dönüşüm: Veri setinde yer alan tüm gözlemlerin p. inci kuvvetinin alınarak yapıldığı dönüşümdür. Bu dönüşüm uygulanırken verinin kaçıncı kuvvetinin alınacağına şu şekilde karar verilir:
Veri setindeki her bir değişken için 3. kartil - 1. kartil =IQR
değerleri hesaplanarak logaritması alınır ve karşılık gelen medyan (M) değerlerinin de logaritması alınarak saçılım grafiği çizilir. Buradan log
(IQR)=a+b.log(M) denklemine ait olan eğtim katsayısından faydalanılarak b=1- p olacak şekilde p değeri belirlenir 8.
Karekök dönüşümü: Üstel dönüşüm ile elde edilen p değerin ye 1/2 eşit olması durumunda üstel dönüşüm özel hal olarak karekök dönüşümü adını alır. Bu dönüşüm normalleştirme durumunda kullanılabileceği gibi varyans dengeleme durumunda da kullanılmaktadır 9. Karekök alma işleminden dolayı içinde negatif gözlem olan veri setlerinde bu dönüşümü kullanmadan önce her bir gözleme sabit bir sayı eklenerek veri setindeki tüm gözlemlerin sıfır ve pozitif olması sağlanmalıdır 8.
Arcsinh(x) dönüşümü: Matematikte hiperbolik fonksiyonlar bilinen trigonometrik fonksiyonların anologudur. Temel hiperbolik fonksiyonlar hiperbolik sinüs "sinh", hiperbolik kosinüs "cosh" olarak bilinir. Diğer fonksiyonlar bu iki fonksiyondan türetilmektedir. Hiperbolik fonksiyonlar genellikle difereansiyel denklemlerin çözümünde önemli rol oynayan fonksiyonlardır.
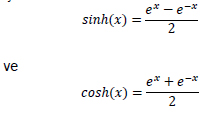
dir. Hiperbolik fonksiyonların bire bir oldukları aralıklarda ters fonksiyonları bulunur. Bu yazılımda sinh fonksiyonunun tersi olan arcsinh fonksiyonu veri dönüşümü yöntemi olarak kullanılmıştır.
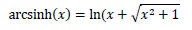
ile dönüşümler yapılmıştır 10.
Box-Cox dönüşümü: Box ve Cox 11 tarafından 1964 yılında yazılan makalelerinde yer verilen Box-Cox dönüşümü yalnızca tek bir parametre olan ya bağlı olup basit bir dönüşümdür. λ ya bağlı olarak Box- Cox dönüşümü
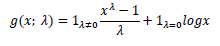
Burada x orijinal yani işlem yapılmamış veri setindeki gözlemleri temsil etmektedir. Λ parametresi maksimum olabilirlik ile tahmin edilebilir.
Yeo-Johnson dönüşümü: 2000 yılında Yeo ve Johnson 12 tarafından önerilen Yeo-Johnson dönüşümü, normal dağılım ile dönüştürülmüş dağılım arasındaki Kullback-Leibler mesafesini en aza indiren lambda değerini (aşağıdaki denklemde) bulmaya çalışır.
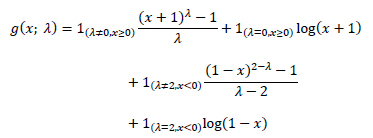
Box-Cox da yer alan parametresi gibi bu formülde yer alan λ parametresi gibi bu formülde yer alan λ parametresi de maksimum olabilirlik ile tahmin edilebilir.
Lambert W (h tipi) ve Lambert W (s tipi) dönüşümü: Georg ve Lambert 13 tarafından Lambert W paketinde yer alan Lambert WxF dönüşümü momentleri kullanarak rastgele bir X değişkenini çözen bir mekanizmadır. Bu yöntem, Box-Cox veya Yeo-Johnson dönüşümü kadar iyi performans göstermez. Bu dönüşümler çarpık (skewed), çok çarpık (heavy-tailed) ve çok ağır çarpık (skewed heavy-tailed) olarak üç tür dönüşümü gerçekleştirir. Geliştirilen yazılımda bu dönüşümlerden çarpık (skewed) ve çok çarpık (heavy-tailed) durumuna yer verilmiştir.
Geliştirilen web tabanlı yazılım: Web tabanlı bu uygulamayı oluşturmak için, R programlama dili temelinde interaktif web tabanlı uygulamaların tasarlanmasına izin veren Shiny kütüphanesi kullanılmıştır 14. Geliştirilen yazılım ayrıca İngilizce dil seçeneğini de içermektedir. Yazılıma ait ana ve alt menüler aşağıda açıklanmıştır.
Veri İşlemleri: Bu web tabanlı uygulamanın ilk aşamasında, veri kümesini içeren dosya yüklenir. Veri analizinde farklı uzantılara sahip en yaygın kullanılan dosya türlerinden olan MS Excel (.xls / .xlsx) ve SPSS (.sav) dosya türleri ile yükleme yapılır.
Dönüşüm: Web tabanlı uygulamanın bu menüsünde Sayısal değişken(ler)‟ sekmesi ile veri setinde yer alan parametrik test yapabilmek adına kontrol edilmesi gereken varsayımlardan olan normallik ve homojen varyanslılık koşullarını bozduğu belirlenen değişkenler seçilir. Seçilen değişkenler için bu sekmede yer alan çalıştır seçeneği kullanılır. Bu şekilde yazılımda yer verilen veri dönüşümü yöntemleri kullanılarak seçilen değişkenler için yazılım gerekli analizleri yapar. Seçilen değişkenler için dönüşümler yapılırken aynı zamanda uygulanan tüm yöntemler için en iyi yönteme karar vermemizi sağlayacak olan Pearson P test istatistiği hesaplanır ve en küçük Pearson P istatistiğine sahip yöntem seçilir. Ayrıca seçilen yöntem ile dönüşüme tabi tutulan yeni veri seti ve dönüşümden önce var olan veri seti için yoğunluk grafikleri de verilmektedir. Bu çıktılar bu menüde yer verilen Sayfayı yazdır butonu ile yazdırılabilir. Şekil 1 Dönüşüm menüsünü göstermektedir.
Ek olarak bu menüde yazılım çalıştırıldıktan sonra seçilen en iyi yöntemle dönüştürülmüş veri setinin MS Excel (.xls / .xlsx) formatında indirilmesini sağlayan Dönüştürülmüş veriyi indir butonu vardır. Veri dönüşümü sonrası daha tutarlı Pearson P istatistiği hesaplayabilmek için tekrarlı 5-katlı çapraz geçerlilik ve birini dışında bırakma çapraz geçerlilik yeniden örnekleme yöntemleri yazılımda kullanıcılara seçmeli olarak sunulmaktadır. Tekrarlı n-katlı çapraz geçerlilik yönteminde veriler öncelikle n parçaya ayrılır ve kullanılan model n parça için uygulanır. n parçadan bir tanesi test için kullanılırken, diğer n-1 parça modelin eğitimi için kullanılır. Elde edilen değerlerin ortalaması, çapraz geçerlilik yöntemi için değerlendirilir 15. Birini dışında bırakma çapraz geçerlilik yöntemi ise eğitim veri setinde ayırdığı bir gözlem hariç diğer gözlemleri kullanıp ayırdığı gözlem üzerinde test verisini değerlendirmektedir 16.
Geliştirilmiş interaktif web uygulamasının erişilebilirliği ve alıntılanması: Geliştirilen web tabanlı yazılıma http://biostatapps.inonu.edu.tr/VDY/ adresinden ücretsiz olarak erişilebilir. Bilimsel çalışmalarda yazılımın kaynak gösterilmesi Arslan, A. K. , Tunc, Z. & Colak, C. VDY: Veri Dönüşüm Yazılımı [Web-tabanlı yazılım] ile yapılmaktadır. Bu yazılımın grafik ara yüzünün geliştirilmesinde shiny 14 ve shinydashboard 17 kütüphaneleri, arka planda çalışan uygulamalarda ise bestNormalize 18 kütüphanesi kullanıldı.


)
)
)
)
)
